
 Events
Events Latest images
Latest imagesDenkverbot
Page 1 of 50
Page 1 of 50 • 1, 2, 3 ... 25 ... 50 ![]()

 Denkverbot
Denkverbot
 by Guest 9/23/2018, 17:57
by Guest 9/23/2018, 17:57
aben wrote:Speare Shaker wrote:aben wrote:
ali, ipak, mozak ni računalo, niti se ponaša ko računalo. defragmentacija je preslagivanje, a snovi to nisu.
Ma to je ionako od početka zamišljeno samo kao zgodna analogija. :) Isto kao i one paralele hardware - mozak, software - um. :)
Makar, dalo bi se itekako raspravljati o tome ako govorimo o kvantnim računalima, a znanstvenici i filozofi širom svijeta to rade već neko vrijeme.
jo ne zun ča su to kvantna računala i kako bi rodila, ali ako su computational, algoritamska- nah.
Postoji jako široka lepeza algoritama već sad u ponudi. :)

Guest- Guest

Re: Denkverbot
by aben 9/23/2018, 18:00
opet algoritmi? it wont work. al, daj linkSpeare Shaker wrote:aben wrote:Speare Shaker wrote:aben wrote:
ali, ipak, mozak ni računalo, niti se ponaša ko računalo. defragmentacija je preslagivanje, a snovi to nisu.
Ma to je ionako od početka zamišljeno samo kao zgodna analogija. :) Isto kao i one paralele hardware - mozak, software - um. :)
Makar, dalo bi se itekako raspravljati o tome ako govorimo o kvantnim računalima, a znanstvenici i filozofi širom svijeta to rade već neko vrijeme.
jo ne zun ča su to kvantna računala i kako bi rodila, ali ako su computational, algoritamska- nah.
Postoji jako široka lepeza algoritama već sad u ponudi. :)
_________________
Insofar as it is educational, it is not compulsory;
And insofar as it is compulsory, it is not educational

aben- Posts : 35492
2014-04-16
Re: Denkverbot
by Guest 9/23/2018, 18:03
aben wrote:
Odlična knjiga. Doduše, ne daje neka snažnije, a posebno ne konačne odgovore, ali daje naznake koje čovjeka tjeraju na promišljanje teme.
No, pošteno govoreći, cijela se ta priča o analogiji rada uma poput kvantnih raćunala nije pokazala posebno vitalnom. Za sad, a vidjet ćemo što će donijeti budućnost.
Ja nekako naslućujem da će se dogoditi otprilike ono što se dogodilo sa fizikom tijekom tranzicije starih ideja iz kraja 19. stoljeća u one radikalno nove početkom 20,. što je proces koji je eskaliralo pojavom kvantne mehanike. :)
Osim njene matematike koja je prilično jasna manje više svim fizičarima toga doba (dvadesete), tada ju je dobro razumjelo možda dvoje ili troje ljudi na svijetu.
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:06
aben wrote:opet algoritmi? it wont work. al, daj linkSpeare Shaker wrote:aben wrote:Speare Shaker wrote:aben wrote:
ali, ipak, mozak ni računalo, niti se ponaša ko računalo. defragmentacija je preslagivanje, a snovi to nisu.
Ma to je ionako od početka zamišljeno samo kao zgodna analogija. :) Isto kao i one paralele hardware - mozak, software - um. :)
Makar, dalo bi se itekako raspravljati o tome ako govorimo o kvantnim računalima, a znanstvenici i filozofi širom svijeta to rade već neko vrijeme.
jo ne zun ča su to kvantna računala i kako bi rodila, ali ako su computational, algoritamska- nah.
Postoji jako široka lepeza algoritama već sad u ponudi. :)
A joj, ima ih jako puno pa mi se to sad ne da tražiti. :)
No, i ja sam mišljenja da to ipak u konačnici neće funkcionirati i da ćemo u skorije vrijeme doći do radikalno novih spoznaja koji će temeljito promjeniti promišljanja o funkcioniranju uma. :)
Dosadašnja riješenja su u praksi pokazala katastrofalno pogrešna predviđanja u odnosu na ono što su nudili teorijski modeli.
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:08
aben wrote:opet algoritmi? it wont work. al, daj linkSpeare Shaker wrote:aben wrote:Speare Shaker wrote:aben wrote:
ali, ipak, mozak ni računalo, niti se ponaša ko računalo. defragmentacija je preslagivanje, a snovi to nisu.
Ma to je ionako od početka zamišljeno samo kao zgodna analogija. :) Isto kao i one paralele hardware - mozak, software - um. :)
Makar, dalo bi se itekako raspravljati o tome ako govorimo o kvantnim računalima, a znanstvenici i filozofi širom svijeta to rade već neko vrijeme.
jo ne zun ča su to kvantna računala i kako bi rodila, ali ako su computational, algoritamska- nah.
Postoji jako široka lepeza algoritama već sad u ponudi. :)
nema linka jer nema algoritama ni softwarea za kvantno računalo. to je jedan od većih problema nitko nezna kako napisati kodirati software i operativni sistem za kvantno računalo. to je BIG problem. kvantno računalo radi na temperaturi malo većoj od apsolutne nule i to hlađenje matične ploče je BIG problem i još veći problem kako to računalo povezati sa periferijom koja radi na sobnoj temperaturi. LOT OF PROBLEMS TO SOLVE.
Guest- Guest
Re: Denkverbot
by aben 9/23/2018, 18:08
Speare Shaker wrote:aben wrote:
Odlična knjiga. Doduše, ne daje neka snažnije, a posebno ne konačne odgovore, ali daje naznake koje čovjeka tjeraju na promišljanje teme.
No, pošteno govoreći, cijela se ta priča o analogiji rada uma poput kvantnih raćunala nije pokazala posebno vitalnom. Za sad, a vidjet ćemo što će donijeti budućnost.
Ja nekako naslućujem da će se dogoditi otprilike ono što se dogodilo sa fizikom tijekom tranzicije starih ideja iz kraja 19. stoljeća u one radikalno nove početkom 20,. što je proces koji je eskaliralo pojavom kvantne mehanike. :)
Osim njene matematike koja je prilično jasna manje više svim fizičarima toga doba (dvadesete), tada ju je dobro razumjelo možda dvoje ili troje ljudi na svijetu.
uopće mi ni jasno ča su to kvantna računala. kad bi čovik načini stroj ki more misliti ko čovik, mislin da se izraz računalo uopće više ne bi moro koristiti, čaviše, mislin da bi kvantno računalo tribalo kompjuter da bi izračunavalo:)
_________________
Insofar as it is educational, it is not compulsory;
And insofar as it is compulsory, it is not educational
aben- Posts : 35492
2014-04-16
Re: Denkverbot
by Guest 9/23/2018, 18:08
violator wrote:Gnječ wrote:aben wrote:da, ni precizno.
možda nojbolje da svak reče koliko vanjskoga života imo. s tin da bi se tribalo utvrditi ča je to vanjski život. je li gljedanje televizije vanjski život, sponje, ili samo ono van kuće, broji li se rad van kuće pod život i sl.
ako ja napišem post u bilo koje doba dana a ti mi odgovoriš na post u roku par minuta ili odmah a nisi logiran od prije onda si stalno na forumu ne logiran ali stalno škicaš na štekatu.
Ili ti, kao drug Sejtan, mozda ne odgovori odmah jer mora napisati prvo esej u Wordu. :-D Zatim sve to zajedno, po mogucnosti, citav topic sacuvati oliti sejvati, ne bi li u svakom trenutku mogao lupiti screenshot ili navesti datum gdje je sto zapisano. :-D Ako to ne mirise na luzera, onda ne znam.. :-D
Assumption is the mother of all fuckups.


Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:15
Gnječ wrote:aben wrote:
opet algoritmi? it wont work. al, daj link
nema linka jer nema algoritama ni softwarea za kvantno računalo.
Kao prvo, ovdje i nije bila riječ (bar ja to tako nisam shvatio) o algoritmima za QC nego o algoritmima općenito, ali i u kontekstu načina funkcioniranja ljudskog uma. Ne možemo isključiti tu opciju, makar nam se intuitivno ne čini plauzibilnom, ali niti qm nije intuitivna disciplina pa je svejedno najvitalniji dio moderne fizike koja je valjda najvitalnija od svih realnih prirodnih znanosti i čini temelj za kemiju i biologiju kao prirodne znanosti.
Kao drugo, očito se nisi potrudio čak niti utipkati pojam u Google inače...
Quantum Computer Algorithms
http://www.karlin.mff.cuni.cz/~holub/soubory/moscathesis.pdf
Last edited by Speare Shaker on 9/23/2018, 18:16; edited 1 time in total
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:16
Inače sad moram ići, a vratim se kasno navečer.
Pozdrav u smiraj svete nedilje. :)
Pozdrav u smiraj svete nedilje. :)
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:19
Speare Shaker wrote:Inače sad moram ići, a vratim se kasno navečer.
Pozdrav u smiraj svete nedilje. :)
vidim sklizak ti teren kiksaš sa znanjem nešto mogli bi te prolit katranom i posuti perjem koliko lažeš pa sad bježiš.
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 18:21
Speare Shaker wrote:Gnječ wrote:aben wrote:
opet algoritmi? it wont work. al, daj link
nema linka jer nema algoritama ni softwarea za kvantno računalo.
Kao prvo, ovdje i nije bila riječ (bar ja to tako nisam shvatio) o algoritmima za QC nego o algoritmima općenito, ali i u kontekstu načina funkcioniranja ljudskog uma. Ne možemo isključiti tu opciju, makar nam se intuitivno ne čini plauzibilnom, ali niti qm nije intuitivna disciplina pa je svejedno najvitalniji dio moderne fizike koja je valjda najvitalnija od svih realnih prirodnih znanosti i čini temelj za kemiju i biologiju kao prirodne znanosti.
Kao drugo, očito se nisi potrudio čak niti utipkati pojam u Google inače...
Quantum Computer Algorithms
http://www.karlin.mff.cuni.cz/~holub/soubory/moscathesis.pdf
Assumption is the mother of all fuckups.
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 19:48
Fibica wrote:Violator tko ti je falio? Ja? :D
Ma i ti si mi nedostajala. :-)
Cak mi i Metkino trcanje pocasnih krugova po forumu katkad nedostaje. Onako, pozelim je docekati iza nekog ugla i samo ispruziti tavu. :-D :-P
Stojte mi dobro. :-)
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 20:52
evo ti zato malo bivših jeseni ispod moje lipeviolator wrote:Fibica wrote:Violator tko ti je falio? Ja? :D
Ma i ti si mi nedostajala. :-)
Cak mi i Metkino trcanje pocasnih krugova po forumu katkad nedostaje. Onako, pozelim je docekati iza nekog ugla i samo ispruziti tavu. :-D :-P
Stojte mi dobro. :-)


Guest- Guest



Re: Denkverbot
by Guest 9/23/2018, 22:05
Gnječ wrote:Speare Shaker wrote:Inače sad moram ići, a vratim se kasno navečer.
Pozdrav u smiraj svete nedilje. :)
vidim sklizak ti teren kiksaš sa znanjem nešto mogli bi te prolit katranom i posuti perjem koliko lažeš pa sad bježiš.
Lakrdijašu. :)
Guest- Guest
Re: Denkverbot
by Guest 9/23/2018, 22:05
Gnječ wrote:Speare Shaker wrote:Gnječ wrote:aben wrote:
opet algoritmi? it wont work. al, daj link
nema linka jer nema algoritama ni softwarea za kvantno računalo.
Kao prvo, ovdje i nije bila riječ (bar ja to tako nisam shvatio) o algoritmima za QC nego o algoritmima općenito, ali i u kontekstu načina funkcioniranja ljudskog uma. Ne možemo isključiti tu opciju, makar nam se intuitivno ne čini plauzibilnom, ali niti qm nije intuitivna disciplina pa je svejedno najvitalniji dio moderne fizike koja je valjda najvitalnija od svih realnih prirodnih znanosti i čini temelj za kemiju i biologiju kao prirodne znanosti.
Kao drugo, očito se nisi potrudio čak niti utipkati pojam u Google inače...
Quantum Computer Algorithms
http://www.karlin.mff.cuni.cz/~holub/soubory/moscathesis.pdf
Assumption is the mother of all fuckups.
E, vidiš ti to. :)
Guest- Guest
Re: Denkverbot
by aben 9/23/2018, 23:39
https://en.wikipedia.org/wiki/Principality_of_Hutt_River
_________________
Insofar as it is educational, it is not compulsory;
And insofar as it is compulsory, it is not educational
aben- Posts : 35492
2014-04-16
Re: Denkverbot
by Guest 9/24/2018, 08:30
Powerfull New Algorithm Is a Big Step Towards Whole-Brain Simulation
By Shelly Fan Mar 21, 2018
The renowned physicist Dr. Richard Feynman once said: “What I cannot create, I do not understand. Know how to solve every problem that has been solved.”
An increasingly influential subfield of neuroscience has taken Feynman’s words to heart. To theoretical neuroscientists, the key to understanding how intelligence works is to recreate it inside a computer. Neuron by neuron, these whizzes hope to reconstruct the neural processes that lead to a thought, a memory, or a feeling.
With a digital brain in place, scientists can test out current theories of cognition or explore the parameters that lead to a malfunctioning mind. As philosopher Dr. Nick Bostrom at the University of Oxford argues, simulating the human mind is perhaps one of the most promising (if laborious) ways to recreate—and surpass—human-level ingenuity.
There’s just one problem: our computers can’t handle the massively parallel nature of our brains. Squished within a three-pound organ are over 100 billion interconnected neurons and trillions of synapses.
Even the most powerful supercomputers today balk at that scale: so far, machines such as the K computer at the Advanced Institute for Computational Science in Kobe, Japan can tackle at most ten percent of neurons and their synapses in the cortex.
This ineptitude is partially due to software. As computational hardware inevitably gets faster, algorithms increasingly become the linchpin towards whole-brain simulation.
This month, an international team completely revamped the structure of a popular simulation algorithm, developing a powerful piece of technology that dramatically slashes computing time and memory use.
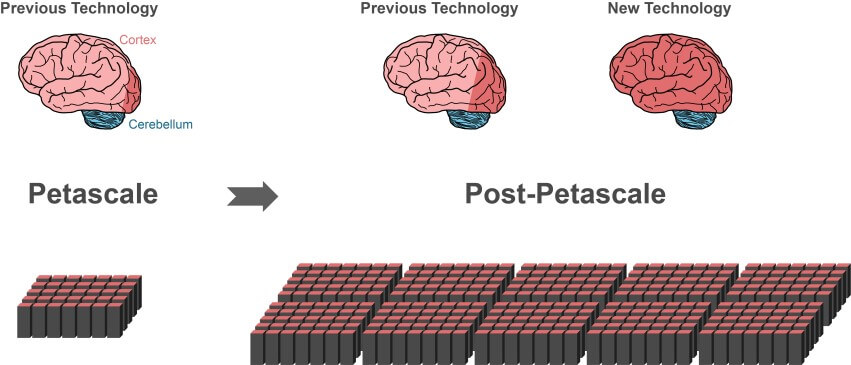
Using today’s simulation algorithms, only small progress (dark red area of center brain) would be possible on the next generation of supercomputers.
However, the new technology allows researchers to simulate larger parts of the brain while using the same amount of computer memory. This makes the new technology more appropriate for future use in supercomputers for whole-brain level simulation.
The new algorithm is compatible with a range of computing hardware, from laptops to supercomputers. When future exascale supercomputers hit the scene—projected to be 10 to 100 times more powerful than today’s top performers—the algorithm can immediately run on those computing beasts.
“With the new technology we can exploit the increased parallelism of modern microprocessors a lot better than previously, which will become even more important in exascale computers,” said study author Jakob Jordan at the Jülich.
Research Center in Germany, who published the work in Frontiers in Neuroinformatics.
“It’s a decisive step towards creating the technology to achieve simulations of brain-scale networks,” the authors said.
The Trouble With Scale
Current supercomputers are composed of hundreds of thousands of subdomains called nodes. Each node has multiple processing centers that can support a handful of virtual neurons and their connections.
A main issue in brain simulation is how to effectively represent millions of neurons and their connections inside these processing centers to cut time and power.
One of the most popular simulation algorithms today is the Memory-Usage Model. Before scientists simulate changes in their neuronal network, they need to first create all the neurons and their connections within the virtual brain using the algorithm.
Here’s the rub: for any neuronal pair, the model stores all information about connectivity in each node that houses the receiving neuron—the postsynaptic neuron.
In other words, the presynaptic neuron, which sends out electrical impulses, is shouting into the void; the algorithm has to figure out where a particular message came from by solely looking at the receiver neuron and data stored within its node.
It sounds like a strange setup, but the model allows all the nodes to construct their particular portion of the neural network in parallel. This dramatically cuts down boot-up time, which is partly why the algorithm is so popular.
But as you probably guessed, it comes with severe problems in scaling. The sender node broadcasts its message to all receiver neuron nodes. This means that each receiver node needs to sort through every single message in the network—even ones meant for neurons housed in other nodes.
That means a huge portion of messages get thrown away in each node, because the addressee neuron isn’t present in that particular node. Imagine overworked post office staff skimming an entire country’s worth of mail to find the few that belong to their jurisdiction. Crazy inefficient, but that’s pretty much what goes on in the Memory-Usage Model.
The problem becomes worse as the size of the simulated neuronal network grows. Each node needs to dedicate memory storage space to an “address book” listing all its neural inhabitants and their connections. At the scale of billions of neurons, the “address book” becomes a huge memory hog.
Size Versus Source
The team hacked the problem by essentially adding a zip code to the algorithm. Here’s how it works. The receiver nodes contain two blocks of information. The first is a database that stores data about all the sender neurons that connect to the nodes.
Because synapses come in several sizes and types that differ in their memory consumption, this database further sorts its information based on the type of synapses formed by neurons in the node.
This setup already dramatically differs from its predecessor, in which connectivity data is sorted by the incoming neuronal source, not synapse type. Because of this, the node no longer has to maintain its “address book.”
“The size of the data structure is therefore independent of the total number of neurons in the network,” the authors explained.
The second chunk stores data about the actual connections between the receiver node and its senders. Similar to the first chunk, it organizes data by the type of synapse. Within each type of synapse, it then separates data by the source (the sender neuron).
In this way, the algorithm is far more specific than its predecessor: rather than storing all connection data in each node, the receiver nodes only store data relevant to the virtual neurons housed within.
The team also gave each sender neuron a target address book. During transmission the data is broken up into chunks, with each chunk containing a zip code of sorts directing it to the correct receiving nodes.
Rather than a computer-wide message blast, here the data is confined to the receiver neurons that they’re supposed to go to.
Speedy and Smart
The modifications panned out.
In a series of tests, the new algorithm performed much better than its predecessors in terms of scalability and speed. On the supercomputer JUQUEEN in Germany, the algorithm ran 55 percent faster than previous models on a random neural network, mainly thanks to its streamlined data transfer scheme.
At a network size of half a billion neurons, for example, simulating one second of biological events took about five minutes of JUQUEEN runtime using the new algorithm. Its predecessor clocked in at six times that.
This really “brings investigations of fundamental aspects of brain function, like plasticity and learning unfolding over minutes…within our reach,” said study author Dr. Markus Diesmann at the Jülich Research Centre.
As expected, several scalability tests revealed that the new algorithm is far more proficient at handling large networks, reducing the time it takes to process tens of thousands of data transfers by roughly threefold.
“The novel technology profits from sending only the relevant spikes to each process,” the authors concluded. Because computer memory is now uncoupled from the size of the network, the algorithm is poised to tackle brain-wide simulations, the authors said.
While revolutionary, the team notes that a lot more work remains to be done. For one, mapping the structure of actual neuronal networks onto the topology of computer nodes should further streamline data transfer. For another, brain simulation software needs to regularly save its process so that in case of a computer crash, the simulation doesn’t have to start over.
“Now the focus lies on accelerating simulations in the presence of various forms of network plasticity,” the authors concluded. With that solved, the digital human brain may finally be within reach.
Shelly Xuelai Fan is a neuroscientist at the University of California, San Francisco, where she studies ways to make old brains young again. In addition to research, she's also an avid science writer with an insatiable obsession with biotech, AI and all things neuro.
https://singularityhub.com/2018/03/21/powerful-new-algorithm-is-a-big-step-towards-whole-brain-simulation/#sm.000093njut1sxdrgyi51sgugil1ei
By Shelly Fan Mar 21, 2018
The renowned physicist Dr. Richard Feynman once said: “What I cannot create, I do not understand. Know how to solve every problem that has been solved.”
An increasingly influential subfield of neuroscience has taken Feynman’s words to heart. To theoretical neuroscientists, the key to understanding how intelligence works is to recreate it inside a computer. Neuron by neuron, these whizzes hope to reconstruct the neural processes that lead to a thought, a memory, or a feeling.
With a digital brain in place, scientists can test out current theories of cognition or explore the parameters that lead to a malfunctioning mind. As philosopher Dr. Nick Bostrom at the University of Oxford argues, simulating the human mind is perhaps one of the most promising (if laborious) ways to recreate—and surpass—human-level ingenuity.
There’s just one problem: our computers can’t handle the massively parallel nature of our brains. Squished within a three-pound organ are over 100 billion interconnected neurons and trillions of synapses.
Even the most powerful supercomputers today balk at that scale: so far, machines such as the K computer at the Advanced Institute for Computational Science in Kobe, Japan can tackle at most ten percent of neurons and their synapses in the cortex.
This ineptitude is partially due to software. As computational hardware inevitably gets faster, algorithms increasingly become the linchpin towards whole-brain simulation.
This month, an international team completely revamped the structure of a popular simulation algorithm, developing a powerful piece of technology that dramatically slashes computing time and memory use.
Using today’s simulation algorithms, only small progress (dark red area of center brain) would be possible on the next generation of supercomputers.
However, the new technology allows researchers to simulate larger parts of the brain while using the same amount of computer memory. This makes the new technology more appropriate for future use in supercomputers for whole-brain level simulation.
The new algorithm is compatible with a range of computing hardware, from laptops to supercomputers. When future exascale supercomputers hit the scene—projected to be 10 to 100 times more powerful than today’s top performers—the algorithm can immediately run on those computing beasts.
“With the new technology we can exploit the increased parallelism of modern microprocessors a lot better than previously, which will become even more important in exascale computers,” said study author Jakob Jordan at the Jülich.
Research Center in Germany, who published the work in Frontiers in Neuroinformatics.
“It’s a decisive step towards creating the technology to achieve simulations of brain-scale networks,” the authors said.
The Trouble With Scale
Current supercomputers are composed of hundreds of thousands of subdomains called nodes. Each node has multiple processing centers that can support a handful of virtual neurons and their connections.
A main issue in brain simulation is how to effectively represent millions of neurons and their connections inside these processing centers to cut time and power.
One of the most popular simulation algorithms today is the Memory-Usage Model. Before scientists simulate changes in their neuronal network, they need to first create all the neurons and their connections within the virtual brain using the algorithm.
Here’s the rub: for any neuronal pair, the model stores all information about connectivity in each node that houses the receiving neuron—the postsynaptic neuron.
In other words, the presynaptic neuron, which sends out electrical impulses, is shouting into the void; the algorithm has to figure out where a particular message came from by solely looking at the receiver neuron and data stored within its node.
It sounds like a strange setup, but the model allows all the nodes to construct their particular portion of the neural network in parallel. This dramatically cuts down boot-up time, which is partly why the algorithm is so popular.
But as you probably guessed, it comes with severe problems in scaling. The sender node broadcasts its message to all receiver neuron nodes. This means that each receiver node needs to sort through every single message in the network—even ones meant for neurons housed in other nodes.
That means a huge portion of messages get thrown away in each node, because the addressee neuron isn’t present in that particular node. Imagine overworked post office staff skimming an entire country’s worth of mail to find the few that belong to their jurisdiction. Crazy inefficient, but that’s pretty much what goes on in the Memory-Usage Model.
The problem becomes worse as the size of the simulated neuronal network grows. Each node needs to dedicate memory storage space to an “address book” listing all its neural inhabitants and their connections. At the scale of billions of neurons, the “address book” becomes a huge memory hog.
Size Versus Source
The team hacked the problem by essentially adding a zip code to the algorithm. Here’s how it works. The receiver nodes contain two blocks of information. The first is a database that stores data about all the sender neurons that connect to the nodes.
Because synapses come in several sizes and types that differ in their memory consumption, this database further sorts its information based on the type of synapses formed by neurons in the node.
This setup already dramatically differs from its predecessor, in which connectivity data is sorted by the incoming neuronal source, not synapse type. Because of this, the node no longer has to maintain its “address book.”
“The size of the data structure is therefore independent of the total number of neurons in the network,” the authors explained.
The second chunk stores data about the actual connections between the receiver node and its senders. Similar to the first chunk, it organizes data by the type of synapse. Within each type of synapse, it then separates data by the source (the sender neuron).
In this way, the algorithm is far more specific than its predecessor: rather than storing all connection data in each node, the receiver nodes only store data relevant to the virtual neurons housed within.
The team also gave each sender neuron a target address book. During transmission the data is broken up into chunks, with each chunk containing a zip code of sorts directing it to the correct receiving nodes.
Rather than a computer-wide message blast, here the data is confined to the receiver neurons that they’re supposed to go to.
Speedy and Smart
The modifications panned out.
In a series of tests, the new algorithm performed much better than its predecessors in terms of scalability and speed. On the supercomputer JUQUEEN in Germany, the algorithm ran 55 percent faster than previous models on a random neural network, mainly thanks to its streamlined data transfer scheme.
At a network size of half a billion neurons, for example, simulating one second of biological events took about five minutes of JUQUEEN runtime using the new algorithm. Its predecessor clocked in at six times that.
This really “brings investigations of fundamental aspects of brain function, like plasticity and learning unfolding over minutes…within our reach,” said study author Dr. Markus Diesmann at the Jülich Research Centre.
As expected, several scalability tests revealed that the new algorithm is far more proficient at handling large networks, reducing the time it takes to process tens of thousands of data transfers by roughly threefold.
“The novel technology profits from sending only the relevant spikes to each process,” the authors concluded. Because computer memory is now uncoupled from the size of the network, the algorithm is poised to tackle brain-wide simulations, the authors said.
While revolutionary, the team notes that a lot more work remains to be done. For one, mapping the structure of actual neuronal networks onto the topology of computer nodes should further streamline data transfer. For another, brain simulation software needs to regularly save its process so that in case of a computer crash, the simulation doesn’t have to start over.
“Now the focus lies on accelerating simulations in the presence of various forms of network plasticity,” the authors concluded. With that solved, the digital human brain may finally be within reach.
Shelly Xuelai Fan is a neuroscientist at the University of California, San Francisco, where she studies ways to make old brains young again. In addition to research, she's also an avid science writer with an insatiable obsession with biotech, AI and all things neuro.
https://singularityhub.com/2018/03/21/powerful-new-algorithm-is-a-big-step-towards-whole-brain-simulation/#sm.000093njut1sxdrgyi51sgugil1ei
Guest- Guest

Re: Denkverbot
by Guest 9/24/2018, 14:03
kic, jebeš šejkera napravi si ovo jelo sve namirnice imaš lako se napravi i bez kvantnog kompjutera. algoritam je jednostavan samo slijedi upute na videu. mljac mljac meni je to jelo super.
Guest- Guest
Page 1 of 50 • 1, 2, 3 ... 25 ... 50 ![]()
Page 1 of 50
Permissions in this forum:
You cannot reply to topics in this forum